![La Ubicación Importa: Geolocalización y Data Science [Parte 1]](https://res.cloudinary.com/rsmglobal/image/fetch/t_default/f_auto/q_auto/https://www.rsm.global/chile/sites/default/files/styles/subpage_hero_banner_mobile_tablet_2x/public/01%20Global%20assets/01_Banners/02_Portraiture%20banners%203840x960px/ani-02-rsm-banner-sub-page.jpg)
Por: José Manuel Peña, Director RSM Chile Technology
Vivimos en un mundo geolocalizado.
Desde los años 60, cuando Estados Unidos comenzó a ubicar sus submarinos mediante satélites, la geolocalización se ha vuelto ubicua. Ya no hay dispositivo o aplicación moderna que no sepa en qué parte del planeta se encuentra las 24 horas del día. Mi teléfono sabe mejor dónde están mis llaves que yo. Y también tienen memoria para saber dónde han estado durante toda su vida.
A consecuencia de lo anterior, existe una vasta base de información geolocalizada (de clientes, consumos, proveedores, etc.) pero muchas empresas todavía no usan esta información en sus procesos de toma de decisiones.
Desde predecir comportamiento de clientes en el mayor proveedor de seguridad de latinoamérica hasta valorizar el trazado del proyecto de transmisión eléctrica más grande de Chile, hemos visto como un buen análisis de información geolocalizada tiene el potencial de crear valor.
En este blog presentamos casos de éxito usando data georreferenciada en proyectos de AI y Analytics, y mostrar cómo puedes usar esta fuente de información en tus proyectos.
Cruzando capas de información: El contexto del territorio.
El valor de la data georreferenciada es el contexto que entrega. Utilizada correctamente, podemos dar contexto a un dato/entidad (un cliente, un terreno, etc.) mediante su cercanía a hitos territoriales relevantes como caminos, ciudades u otras capas de información ad-hoc al problema a resolver.
Por ejemplo, un cliente se acercó con el siguiente problema:
En un proyecto de transmisión eléctrica de larga distancia les faltaba un ítem clave para presupuestar su costo, la indemnizaciones por uso del terreno. Sin entrar en detalles, este costo puede ser más de la mitad del costo total del proyecto y, a pesar de estar regulado, su valor varía enormemente entre diversos predios en vista de su uso y valor comercial (no es lo mismo pasar por un sitio eriazo que por un campo productivo o un parque industrial).
En vista de lo anterior la pregunta se resume en:
¿Cómo generar la tasación masiva de terrenos como parte de la estimación de costo de indemnización?.
Usualmente esto es realizado por tasadores en terreno, pero cuando se quiere realizar a escala (cientos o miles de terrenos en todo chile), hacerlo manualmente es prohibitivo, además de quedar a merced de las diferencias de criterio de una multitud de tasadores locales.
Ante este desafío lo que buscamos fue replicar los atributos que usualmente se usan en una tasación: superficie, infraestructura, producción, etc. Pero si queremos capturar bien el valor de un terreno, tenemos que incorporar el “donde” está emplazado, lo que este caso se tradujo en estimar la cercanía de cada terreno a diversos hitos territoriales relevantes como zonas urbanas, carreteras, tendido eléctrico, etc.
Para esto levantamos múltiples capas de información pública (zonificación de Ministerio de Vivienda y Urbanismo, red eléctrica y vial del Ministerio de Obras Públicas, entre otros) y mediante un proceso de ETL (Extracción, Transformación y Carga de Datos) en Python estimamos para cada terreno su menor distancia hacia cada capa, es decir, la menor distancia de cada terreno a una carretera, una ciudad, una línea eléctrica, etc. De esta manera, pudimos sensibilizar nuestros modelos predictivos al “atractivo territorial” de cada terreno de manera robusta, mejorando la calidad de la estimación.
No todo es tan fácil, si la capa de información que quieres cruzar es muy extensa (como una carretera), o posee muchos elementos puntuales (como zonas urbanas), el proceso puede ser extremadamente lento calculando la distancia de cada terreno contra cada punto de la capa de análisis.
Ante esta dificultad, nuestra estrategia fue “dividir para conquistar”, donde primero dividimos un polígono grande en muchos sub-polígonos (usando algoritmos como estos, ver “Splitting large polygons for faster intersections”), ordenarlos en un K-D Tree en base al centro del polígono, y solo calcular la distancia para el subconjunto más cercano.
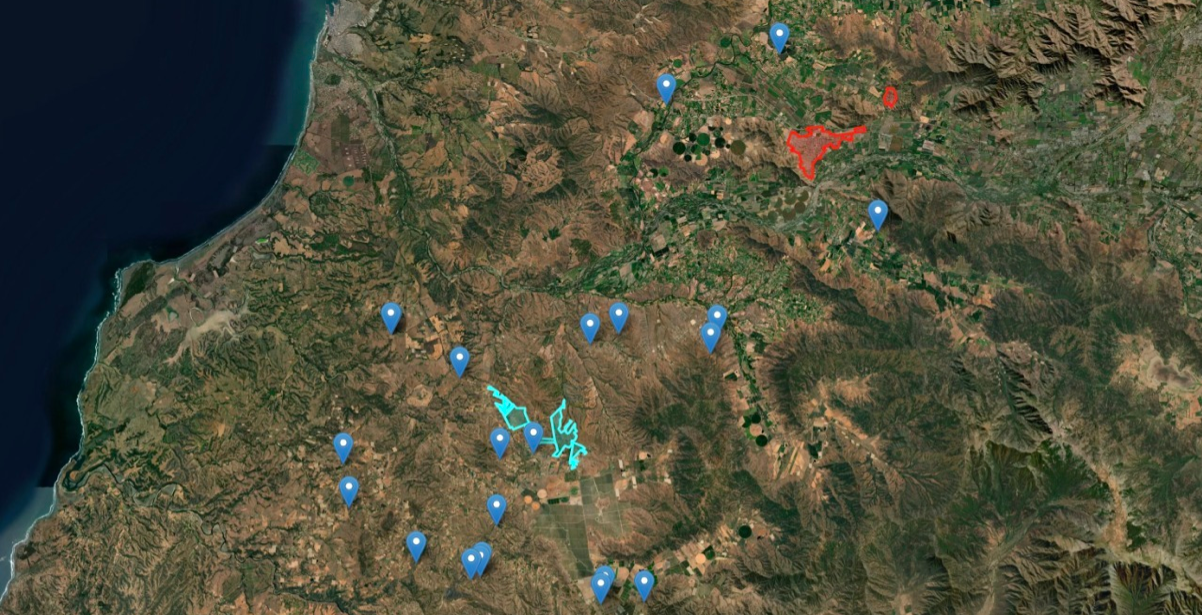
Ejemplo de tasación de terrenos (puntos azules) en el contexto de zonas urbanas (áreas de color) en el sector de Melipilla, Chile.
Aplicando esta estrategia a nuestros modelos predictivos, fuimos capaces de generar un proceso rápido, robusto y eficiente de tasación, capaz de analizar cientos de predios rápidamente, sin costosas idas a terreno.
Y ahora viene lo más interesante, ¿cómo validamos los resultados?, bueno los comparamos con otros estudios realizados de forma manual y fueron analizados por tasadores expertos que confirmaron la calidad de los resultados obtenidos. Esto nos permitió bajar los costos de tasación en más de tres veces en comparación a los procesos tradicionales, obteniendo mejores resultados, robustos y explicables.
Dado este y muchos otros casos “LA UBICACIÓN IMPORTA”. Este es el primero de varios post sobre geolocalización y data science, en los próximos post mostraremos otros interesantes casos de uso.
Revisa:



